Some codes you receive are fun.
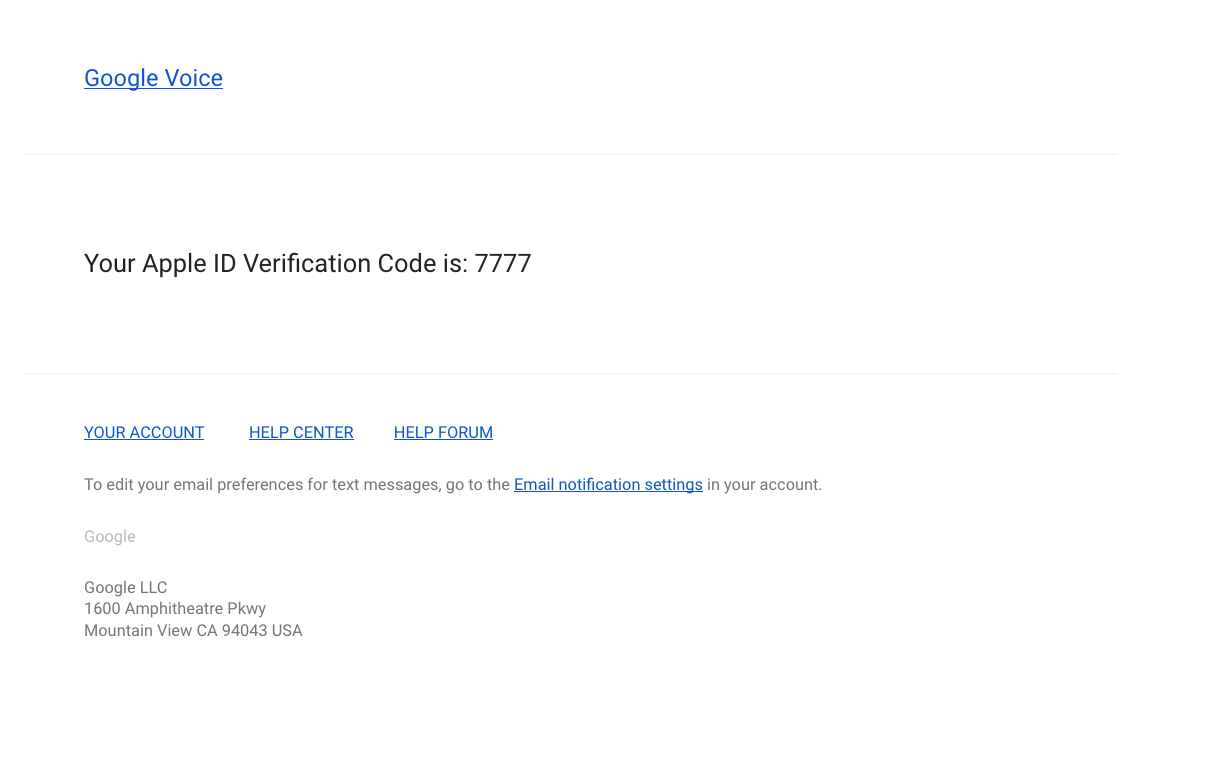
Some codes you receive are fun.
Earlier today, I added a new boot image, OS image, and deployed a new task sequence for our SCCM setup. Took a UEFI laptop that previously PXE-booted successfuly, but this time nothing happened. Tried a different model, still nothing.
I mucked around with DHCP options (specifically, adding Option 60 detailed here with specific steps here). No luck. Laptop would boot up, detect media was present, then try other boot methods as nothing was found.
Started playing around with the changes I made, editing the task sequence to use an older (but still current-versioned) and it worked!
Re-examined the new boot image I uploaded and viewing Properties told me I forgot to enable PXE support on it. D’oh!
I had a Win10 Ent boot image loaded into SCCM and distributed. However, I needed to enable command support as well as add some more drivers. Making the changes within the boot image’s properties went fine, but when I tried distributing the modified image, I rec’d the following error:
“Failed to make a copy of source WIM file due to error 2”;
Going into the location where my boot image was stored, I saw two were created: the original boot image I started with and boot.<uuid>.<uuid>.wim. I went into the properties of the boot image > Data Source > and browsed to just the boot.wim file.
I can distribute the modified image once more.
Consulted: https://social.technet.microsoft.com
I had to compare separate PCAP files, but it seems Wireshark isn’t capable as that’d bypass its function of monitoring traffic in a single instance.
However, on OS X, run:
open -n /Applications/Wireshark.app
Another instance launches and I used it to open the second PCAP file.
Source: https://osqa-ask.wireshark.org/
Problem:
DHCP server hosted in VPC wasn’t issuing addresses to clients.
Scenario:
DHCP server resides in a VPC which tunnels to our office LAN. Because of the particular solutions I’m implementing, the DHCP server must be in AWS, not on-prem.
The test client resides on VLAN X and the router is properly configured. There’s also another device on the same VLAN that acts as a DHCP relay agent, forwarding DHCP broadcasts to the DHCP server in the VPC.
Troubleshooting:
And that’s where I got stopped. Monitoring the DHCP server’s network, it would receive traffic from the DHCP relay, but do absolutely nothing with it. I’ve tried it with firewalls on and off. No luck.
Solution – Part 1
After running BPA, it didn’t dawn on me that DHCP server would crap out if the server’s NIC wasn’t configured w/ a static IP. As a test, I configured the DHCP server w/ a static address and it worked!
However…
Solution – Part 2
DO. NOT. CONFIGURE. EC2 INSTANCES. WITH. STATIC. ADDRESSES!!!! Period. No exceptions. No way around it.
I did this once before when I was just starting out with AWS/VPC and it absolutely WRECKS your chances of getting into (or recovering) an AMI that you lose connectivity to. All of the AWS recovery tools rely on the default networking, and configuring anything that’s not default within an AMI’s OS breaks the tools’ ability to function.
So, I added a second NIC to the server and manually configured that, leaving the default NIC alone so recovery tools can work.
I’m introducing DHCP into my two-controller AD environment and ran into the following error:
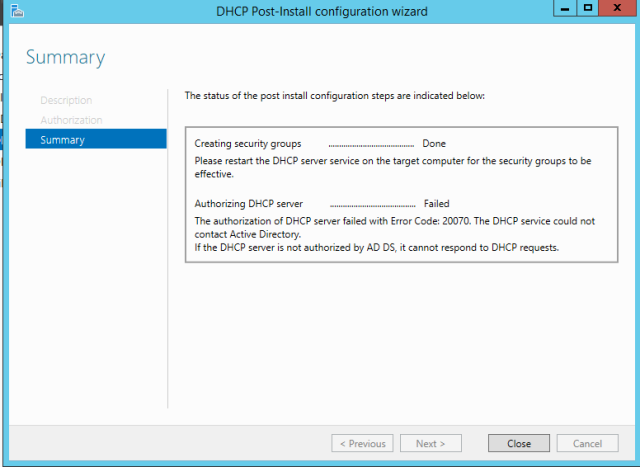
Troubleshooting Steps:
1. Account used to install DHCP was in Enterprise Admins. Also added to Domain Admins group
2. Removed DHCP role from second controller, rebooted
3. Removed DHCP role from first controller, rebooted
4. Ran gpupdate /force on second controller, to ensure security group membership applied
5. Ran gpupdate /force on first controller, to ensure security group membership applied
6. Used ASDI Edit > Configuration > Services > NetService to delete both the DHCP objects
7. Forced replication
8. Re-added DHCP Role
After trying to commit, received the following error… again:
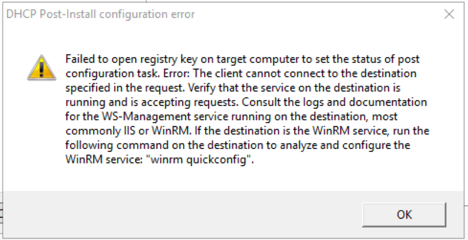
9. Enabled WinRM in GPO
10. Removed DHCP role from first controller
11. Deleted DHCP objects in ASDI Edit again
12. Forced replication
13. Re-added DHCP role
14. Rebooted
15. Success!!
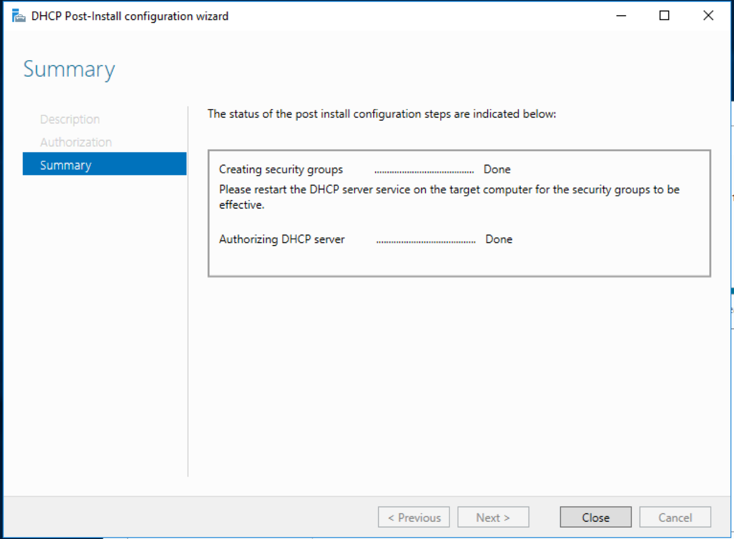
What was the problem?
WinRM policy was preventing GUI to complete installation. The policy has since been restored back to how it was before, blocking WinRM once more.
I just attended the International Privacy and Security Forum in D.C., and many sessions focused on the impending GDPR. Some presented on requirements presented by specific articles, like Article 30, while other sessions shared what major corporations were doing to work towards “compliance”.
This is one of several posts where I’ll share what I learned, provide my own thoughts around GDPR strategies, and hopefully develop a framework myself and others can use to launch a GDPR strategy within an organization.
ike esp from {<localLAN1>, <localLAN2>, <localLAN3>} to <remoteLAN> \
peer <remoteVPNGateway> \
main auth <authType> enc <encType> group <Group> lifetime <time> \
quick auth <authType> enc <encType> group <Group> lifetime <time> \
srcid <localVPNGateway> \
psk “<psk>”
Example:
ike esp from {0.0.0.0/0, 0.0.0.00, 0.0.0.0/0} to 0.0.0.0/0 \
peer 0.0.0.0 \
main auth hmac-sha1 enc aes-128 group modp1024 lifetime 28800 \
quick auth hmac-sha1 enc aes-128 group modp1024 lifetime 3600 \
srcid 0.0.0.0\
psk "as;dlkfj;laksdjf;laskdjfa;slkdjf;alskdfjl;sadkfj"
Important Notes:
Been racking my brain for the past week. FileVault 2 enables file with an institutional recovery key, but as soon as you log in again after the reboot, it’ll freeze at either the 50% or 75% in the progress bar. HOWEVER, you can successfully authenticate when booting with Safe Mode.
At first I thought it was our AV solution that installed unsigned extensions and SIP was somehow involved. However I ruled that out after testing. Finally I thought to test my profiles (there’s ~23 of them) and found that one in particular breaks FileVault.
The culprit is:
com.apple.loginwindow
Forced
mcx_preference_settings
AdminMayDIsableMCX
Obviously this isn’t the whole profile. I just included the main parts.
In Googling I also found one other person experiencing this issue (see here). As of yet I don’t know why this key breaks FV. Time to do more research.
This configures System Preferences > Bluetooth > Advanced…
To uncheck “Open Bluetooth Setup Assistant at startup if no keyboard is detected”, run:
sudo defaults write /Library/Preferences/com.apple.Bluetooth.plist BluetoothAutoSeekKeyboard false
To uncheck “Open Bluetooth Setup Assistant at startup if no mouse or trackpad is detected”, run:
sudo defaults write /Library/Preferences/com.apple.Bluetooth.plist BluetoothAutoSeekPointingDevice
Still trying to figure out a command to disable the third option, “Allow Bluetooth devices to wake this computer”.